磁盘在系统中的命名
| 设备名称 |
分区信息 |
设备类型 |
| /dev/sda |
/dev/sda1 |
第一块物理硬盘第一分区 |
| /dev/sdb |
/dev/sdb2 |
第二块硬盘第二个分区 |
| /dev/vdd |
/dev/vdd4 |
第四块虚拟硬盘的第四个分区 |
sd开头,sda代表第一块盘,sdb代表第二块,sda1代表第一块盘的第一个分区
sd中的d代表disk,s 代表 sata 或 sas 接口
我们知道硬盘的接口标准还有 Nvme(Non-Volatile Memory Express,非易失性内存主机控制器接口规范),如果你是固态盘那建议用 Nvme,如果是 Nvme 接口,那么硬盘的命名规则为 “nvmeXnY”
1、“nvme” 是 NVMe 协议的缩写;
2、“X” 代表 NVMe 控制器 / 插槽的编号;0 代表第一个控制器或插槽, 1 代表第二个 3、“nY” 代表 NVMe 命名空间的编号。n1 代表某一个控制器的第 1 个命名空间,命名空间 namespace 相当于对硬盘做了虚拟化,一个命名空间就是一块逻辑盘,通常情况一个硬盘就一个命名空间
所以关于完全可以这么记忆 nvme 代表协议:
nvme0:代表主板上的第一个控制或插槽编号,用来插入硬盘的 nvme1:代表主板上的第二个控制或插槽编号,用来插入硬盘的
nvme0—n1:代表 0 号插槽里插入了第一块硬盘,连在一起叫 nvme0n1 nvme0—n2:代表 0 号插槽里插入了第二块硬盘
nvme0—n1—-p1:代表 0 号控制器插槽插入的第一块硬盘的第一个分区, nvme0—n1—-p2:代表 0 号控制器插槽插入的第一块硬盘的第二个分区 nvme0—n1—-p2:代表 0 号控制器插槽插入的第一块硬盘的第二个分区
nvme1—n1—-p1:代表 1 号控制器插槽插入的第一块硬盘的第一个分区 nvme1—n1—-p2:代表 1 号控制器插槽插入的第一块硬盘的第二个分区 nvme1—n1—-p2:代表 1 号控制器插槽插入的第一块硬盘的第二个分区
例如 1、Nvme0:第一块 2、Nvme1:第二块硬盘 3、Nvme0n1:第一块硬盘的第一个 namespace 命名空间,这是一个逻辑概念,一个名空间就相当于一块隔离的硬盘,当今世界都在谈虚拟化,这就相当于硬盘的虚拟化技术,这种 namespace 隔离设计思想在很多地方都会用,包括后面学习到的 docker、k8s 等
NVMe 是一种硬盘接口技术,它是专为固态硬盘(SSD)设计的,比传统的 SATA 和 SAS 接口有更高的性能。
(Namespace)命名空间是 NVMe 设备数据存储的一个重要的逻辑概念,一个 NVMe 存储设备可以被分成多个独立的命名空间,
每一个命名空间被操作系统视为一个独立的硬盘。
命名空间的一个主要作用就是数据隔离。这意味着不同的命名空间之间的数据互不干扰,可以独立地进行管理。
这种隔离功能有助于保护数据安全,防止不同应用之间的数据混淆或篡改。
在一些特殊的场景下,命名空间的功能非常有用。例如,在数据中心环境中,一台物理服务器可能会被虚拟化为多个虚拟机,
每个虚拟机都运行着自己的操作系统和应用程序。如果这台服务器上有一块 NVMe 硬盘,我们可以为每个虚拟机分配一个命名空间。
每个虚拟机会认为自己独占了一块 NVMe 硬盘,而实际上,这些虚拟机都在共享同一块物理硬盘。
这样,就实现了物理硬盘资源的共享,同时保证了每个虚拟机之间的数据隔离。
分区主要分为三类:主分区 <—扩展分区 <—逻辑分区
1、逻辑分区属于扩展分区,扩展分区属于主分区
2、主分区又叫做引导分区,是可以安装系统的分区
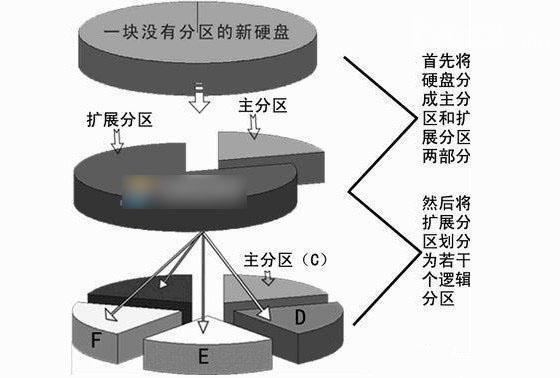
常见的磁盘分区格式有两张,MBR 分区和 GPT 分区:
- MBR 分区,MBR 的意思是 “主引导记录”。MBR 最大支持 2 TB 容量,在容量方面存在着极大的瓶颈。并且只支持创建最多 4 个主分区,。而 GPT 分区方式就没有这些限制
- GPT 分区(ubuntu 装系统默认就是 GPT 分区),GPT 意为 GUID 分区表,它支持的磁盘容量比 MBR 大得多。这是一个正逐渐取代 MBR 的新标准,它是由 UEFI 辅住而形成的,将来 UEFI 用于取代老旧的 BIOS,而 GPT 则取代老旧的 MBR。
1
2
|
fdisk # 用于 MBR 格式
gdisk # 用于 GPT 格式
|
查看设备详情, 以及分区的情况
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@localhost ~]# lsblk /dev/sda
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 10G 0 disk
├─sda1 8:1 0 500M 0 part /boot
├─sda2 8:2 0 1G 0 part [SWAP]
└─sda3 8:3 0 8.5G 0 part /
[root@localhost ~]# lsblk /dev/sdb
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 0 20G 0 disk
[root@localhost ~]# lsblk /dev/sdc
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdc 8:32 0 20G 0 disk
|
fdisk 工具
适用于磁盘小于 2TB 的磁盘,分区类型 MBR,主分区 4 或主分区 3 + 扩展分区(逻辑分区 +…),分区后需要保存后才能生效
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
[root@localhost ~]# fdisk /dev/sdb
Command (m for help): m #输入m列出常用的命令
Command action
a toggle a bootable flag #切换分区启动标记
b edit bsd disklabel #编辑sdb磁盘标签
c toggle the dos compatibility flag #切换dos兼容模式
d delete a partition #删除分区
l list known partition types #显示分区类型
m print this menu #显示帮助菜单
n add a new partition #新建分区
o create a new empty DOS partition table #创建新的空白分区表
p print the partition table #显示分区表的信息
q quit without saving changes #不保存退出
s create a new empty Sun disklabel #创建新的Sun磁盘标签
t change a partitions system id #修改分区ID,可以通过l查看id
u change display/entry units #修改容量单位,磁柱或扇区
v verify the partition table #检验分区表
w write table to disk and exit #保存退出
x extra functionality (experts only) #拓展功能
|
1
2
3
4
5
|
优先掌握
n
p
d # 删除一个已有的分区,保存退出后需要执行partprobe命令刷新一下分区表
w
|
主分区最多四个,一般设置三个以内,剩下空间都给扩展分区
gdisk 工具
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
# 需要安装命令
[root@localhost ~]# yum install gdisk -y
[root@localhost ~]# gdisk /dev/sdc
......
Command (? for help): m
b back up GPT data to a file #将GPT数据备份到文件中
c change a partition's name #更改分区的名称
d delete a partition #删除分区
i show detailed information on a partition #显示分区的详细信息
l list known partition types #列出已知的分区类型
n add a new partition #添加一个新的分区
o create a new empty GUID partition table (GPT) #创建一个新的空GUID分区表(GPT)
p print the partition table #打印分区表
q quit without saving changes #没有保存更改就退出
r recovery and transformation options (experts only) #恢复和转换选项(仅限专家使用)
s sort partitions #年代分类分区
t change a partition's type code #不要更改分区的类型代码
v verify disk #验证磁盘
w write table to disk and exit #将表写入磁盘并退出
x extra functionality (experts only) #额外功能(仅限专家使用)
? print this menu #打印菜单
|
1
2
3
4
5
6
|
优先掌握
gdisk 创建分区
n
p
d
w
|
格式化制作文件系统与挂载
磁盘必须格式化制作文件系统,然后挂载才能使用
针对一块硬盘/dev/sdb
可以不分区,直接格式化制作文件系统
1
|
mkfs.xfs /dev/sdb # /dev/sdb整体就是一个分区
|
也可以基于 mbr 或者 gpt 分区方式分区完毕后,针对某一个分区比如 / dev/sdb1 制作文件系统
centos7选择xfs格式作为默认文件系统,而且不再使用以前的ext,仍然支持ext4,xfs专为大数据产生,每个单个文件系统最大可以支持8eb,单个文件可以支持16tb,不仅数据量大,而且扩展性高。还可以通过xfsdump,xfsrestore来备份和恢复。
挂载与卸载
以 / dev/sdb1 为例演示
1
2
3
4
5
6
7
|
[root@localhost ~]# mount /dev/sdb1 /opt/
卸载
umount /dev/sdb1 # 或者umount /opt
强制卸载
umount -l /dev/sdb1 # 或者umount -l /opt
|
设置开机自动挂载
- 将挂载命令写入文件/etc/rc.local(注意这是一个软连接,目标文件初始并没有x执行权限,需要加才行)
- 编辑文件/etc/fstab
1
2
3
|
[root@localhost ~]# sed -i '$a /dev/sdb1 /opt xfs defaults 0 0' /etc/fstab
[root@localhost ~]# tail -1 /etc/fstab
/dev/sdb1 /opt xfs defaults 0 0
|
补充:磁盘挂载mount
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
-t 指定文件系统
-a 挂载/etc/fstab中配置的所有
[root@localhost ~]# mount -t xfs /dev/sdb1 /db1
可以查看到文件系统的uuid并挂载
[root@localhost ~]# blkid | grep sdb1
/dev/sdb1: UUID="10a939a8-d17c-4a0f-9a89-8066ac013855" TYPE="xfs"
[root@localhost ~]# mount UUID="10a939a8-d17c-4a0f-9a89-8066ac013855" /opt
建议配置文件/etc/fstab用uuid
[root@localhost ~]# tail -1 /etc/fstab # 编辑文件,新增一行
UUID="10a939a8-d17c-4a0f-9a89-8066ac013855" /opt xfs defaults 0 0
[root@localhost ~]# mount -a
[root@localhost ~]# df # 查看挂载情况
|
补充:/etc/fstab配置文件编写格式
| 要挂载的设备 |
挂载点(入口) |
文件系统类型 |
挂载参数 |
是否备份 |
是否检查 |
| /dev/sdb1 |
/data |
xfs |
defaults |
0 |
0 |
第一列:device: 这里用来指定你要挂载的文件系统的设备名称或块信息,除了指定设备文件外,也可以使用 UUID、LABEL 来指定分区。
第二列:dir: 指定挂载点的路径;
第三列:type: 指定文件系统的类型, 如 ext3,ext4,xfs 等;
第四列:options: 指定挂载的参数, 默认为 defaults;
| 参数 |
含义 |
| async/sync |
是否同步方式运行,默认 async(异步)。 |
| user/nouser |
是否允许普通用户使用 mount 命令挂载,默认 nouser。 |
| exec/noexec |
是否允许可执行文件执行,默认 exec。 |
| suid/nosuid |
是否允许存在 suid 属性的文件,默认 suid。 |
| auto/noauto |
执行 mount -a 时,此文件系统是否被主动挂载,默认 auto。 |
| rw/ro |
是否只读或者读写模式进行挂载。默认 rw。 |
| defaults |
具有 rw,suid,exec,auto,nouser,async 等默认参数的设定。 |
第五列:dump: 表示该挂载后的文件系统能否被 dump 备份命令作用;
| 选项 |
含义 |
| 0 |
代表不做备份。 |
| 1 |
代表要每天进行备份操作。 |
| 2 |
代表不定日期的进行备份操作。 |
第六列:pass: 这里用来指定如何使用 fsck 来检查硬盘。
| 选项 |
含义 |
| 0 |
代表不检查 |
| 1 |
检查,挂载点为 / 的(即根分区)时候,必须在这里填写 1,其他的都不能填写 1。 |
| 2 |
检查 (当 1 级别检验完成之后进行 2 级别检验) |
制作 swap 分区
查看
1
2
3
4
|
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 1980 186 1571 9 222 1600
Swap: 1023 0 1023
|
制作 swap 分区
1
2
|
[root@localhost ~]# fdisk /dev/sdb # 分出一个1G的硬盘空间
[root@localhost ~]# mkswap /dev/sdb1 # 格式化为swap
|
激活 swap 分区
1
2
3
4
5
6
7
8
9
10
|
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 1980 185 1568 9 225 1601
Swap: 1023 0 1023
[root@localhost ~]# swapon /dev/sdb1 # 激活
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 1980 186 1567 9 225 1600
Swap: 2047 0 2047
[root@localhost ~]#
|
关闭swap分区
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 1980 186 1567 9 225 1600
Swap: 2047 0 2047
[root@localhost ~]# swapon -s
文件名 类型 大小 已用 权限
/dev/sda2 partition 1048572 0 -2
/dev/sdb1 partition 1048572 0 -3
[root@localhost ~]# swapoff /dev/sdb1 # 关闭某一个
[root@localhost ~]# swapon -s
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 1980 185 1570 9 224 1601
Swap: 0 0 0
|
如果磁盘没有过多的分区可用,也可以通过文件增加SWAP空间,本质上还是磁盘
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@localhost ~]# dd if=/dev/zero of=/swap_file bs=1M count=200
[root@localhost ~]# chmod 0600 /swap_file
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 1980 185 1364 9 430 1598
Swap: 0 0 0
[root@localhost ~]# mkswap -f /swap_file
[root@localhost ~]# swapon /swap_file
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 1980 222 1300 9 458 1550
Swap: 199 0 199
|
开机自动挂载新增的swap分区
1
2
3
4
5
|
[root@localhost ~]# blkid | grep /dev/sdb1
/dev/sdb1: UUID="91d30c2d-2b43-40b1-b2b5-6f828c585f97" TYPE="swap" PARTUUID="d3b7649d-54aa-45eb-8bef-dccfe6915413"
[root@localhost ~]# vim /etc/fstab
[root@localhost ~]# tail -1 /etc/fstab
UUID="91d30c2d-2b43-40b1-b2b5-6f828c585f97" swap swap defaults 0 0
|
XFS 文件系统备份与恢复
命令与软件包
1
2
3
4
|
[root@localhost ~]# rpm -qf `which xfsdump`
xfsdump-3.1.7-1.el7.x86_64
[root@localhost ~]# rpm -qf `which xfsrestore`
xfsdump-3.1.7-1.el7.x86_64
|
xfsdump的备份级别有以下两种,默认为0(即完全备份)
1
2
3
4
5
|
0 完全备份
1 <= level <= 9 增量备份:
# ps:增量备份是和第一次的备份(level 0)进行比较,仅备份有差异的文件(level 1)
|
xfsdump 常用参数
1
2
3
4
5
6
|
-l:注意不是大写字母L而是小写,就是指定level,有0~9共10个等级,默认为0,即完整备份。
-L:xfsdump会记录每次备份的session Label,这里可以填写针对此文件系统的简易说明;
-M:xfsdump可以记录存储Media Label,这里可以填写此媒体的简易说明。
-f:后面接产生的文件和destination file 。例如/dev/st0设备文件名或其他一般文件文件名
-I:大写的“i”,从/var/lib/xfsdump/inventory 列出目前备份的信息状态。
|
xfsdump 使用限制
- 必须用 root 权限
- 只能备份已挂载的文件系统
- 只能备份 XFS 文件系统
- 只能用 xfsrestore 解释
- 透过文件系统的 UUID 来分辨备份档,因此不能备份相同 UUID 的文件系统
xfsdump 备份与 xfsrestore 恢复
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# 1、数据备份
# 1.1 先做全量备份,切记“备份的源路径”末尾不要加左斜杠/
注意:
(1)-L与-M后的你起的名字保持一致就行,也方便你记忆
(2)备份的源路径写/dev/sda1这种文件系统名字是通用写法,虽然在centos7.9中写挂载点路径虽然也可以,但是还是推荐用通用的靠谱一些
xfsdump -l 0 -L sdb3_bak -M sdb3_bak -f 全量备份的成果路径1 备份的源路径
# 1.2 再做增量备份
xfsdump -l 1 -L sdb3_bak -M sdb3_bak -f 增量备份的成果路径2 备份的源路径
xfsdump -l 1 -L sdb3_bak -M sdb3_bak -f 增量备份的成果路径3 备份的源路径
xfsdump -l 1 -L sdb3_bak -M sdb3_bak -f 增量备份的成果路径4 备份的源路径
# 2、数据恢复
# 2.1、先恢复全量备份
xfsrestore -f 全量备份的成果路径1 数据恢复的路径
# 2.2、再依次恢复增量
xfsrestore -f 增量备份的成果路径2 数据恢复的路径
xfsrestore -f 增量备份的成果路径2 数据恢复的路径
xfsrestore -f 增量备份的成果路径2 数据恢复的路径
|
LVM(⭐)
我们在对磁盘分区的大小进行规划时,往往不能确定每个分区使用的空间大小,只能凭经验分配一个大小,而我们通常使用的 fdisk、gdisk 等工具对磁盘分区后,每个分区的大小就固定死了,这么做的问题是:
如果分区设置的过大,就白白浪费了磁盘空间;
如果分区设置的过小,就会导致空间不够用的情况出现。
对于分区过小的问题,我们可以重新划分磁盘的分区,或者通过软连接的方式将此分区的目录链接到另外一个分区。这样做虽然能够临时解决问题,但是给管理带来了麻烦
上述问题可以通过 LVM 来解决。
逻辑卷管理LVM是硬盘的一个系统工具。无论在Linux或者其他类似的系统,都是非常的好用。传统分区使用固定大小分区,重新调整大小十分麻烦。但是,LVM可以创建和管理“逻辑”卷,而不是直接使用物理硬盘。可以让管理员弹性的管理逻辑卷的扩大缩小,操作简单,而不损坏已存储的数据。可以随意将新的硬盘添加到LVM,以直接扩展已经存在的逻辑卷。LVM并不需要重启就可以让内核知道分区的存在。
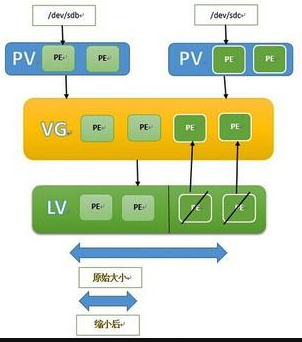
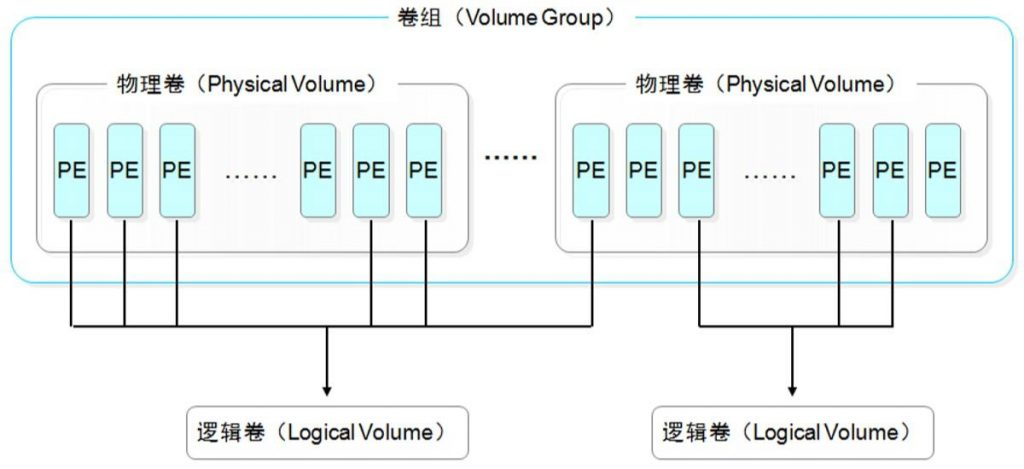 通过 LVM 技术,可以屏蔽掉磁盘分区的底层差异,在逻辑上给文件系统提供了一个卷的概念,然后在这些卷上建立相应的文件系统。下面是 LVM 中主要涉及的一些概念。
通过 LVM 技术,可以屏蔽掉磁盘分区的底层差异,在逻辑上给文件系统提供了一个卷的概念,然后在这些卷上建立相应的文件系统。下面是 LVM 中主要涉及的一些概念。
物理卷(PV):(physical volume),把常规的磁盘设备通过pvcreate命令对其进行初始化,形成了物理卷。其实就是硬盘或分区。(面粉)
卷组(VG):(volume group),把多个物理卷组成一个逻辑的整体,这样卷组的大小就是多个硬盘之和。或者理解就是由一个或多个PV组成的整体。(面团)
逻辑卷(LV):(logical volume),从卷组中划分需要的空间大小出来。用户仅需对其格式化然后即可挂载使用。从VG中切割出的空间用于创建文件系统。(切成馒头)
基本单元(PE):(physical extend),分配的逻辑大小的最小单元,默认为4MB的基本块。(假设分配100MB逻辑空间,则需要创建25个PE)
LVM 优缺点总结
优点:
1、可以在系统运行的状态下动态的扩展文件系统的大小。
2、文件系统可以跨多个磁盘,因此文件系统大小不会受物理磁盘的限制。
3、可以增加新的磁盘到 LVM 的存储池中。
4、可以以镜像的方式冗余重要的数据到多个物理磁盘。
5、可以方便的导出整个卷组到另外一台机器。
缺点:
1、因为加入了额外的操作,存取性能受到影响。
2、当卷组中的一个磁盘损坏时,整个卷组都会受到影响。
解释:LVM 如果有一个磁盘损坏, 整个 lvm 都坏了,lvm 只有动态扩展作用,
方案:底层用 RAID + 上层 LVM = 既有冗余又有动态扩展
3、在从卷组中移除一个磁盘的时候必须使用 reducevg 命令(该命令要求 root 权限, 并且不允许在快照卷组中使用)
LVM 的基本使用
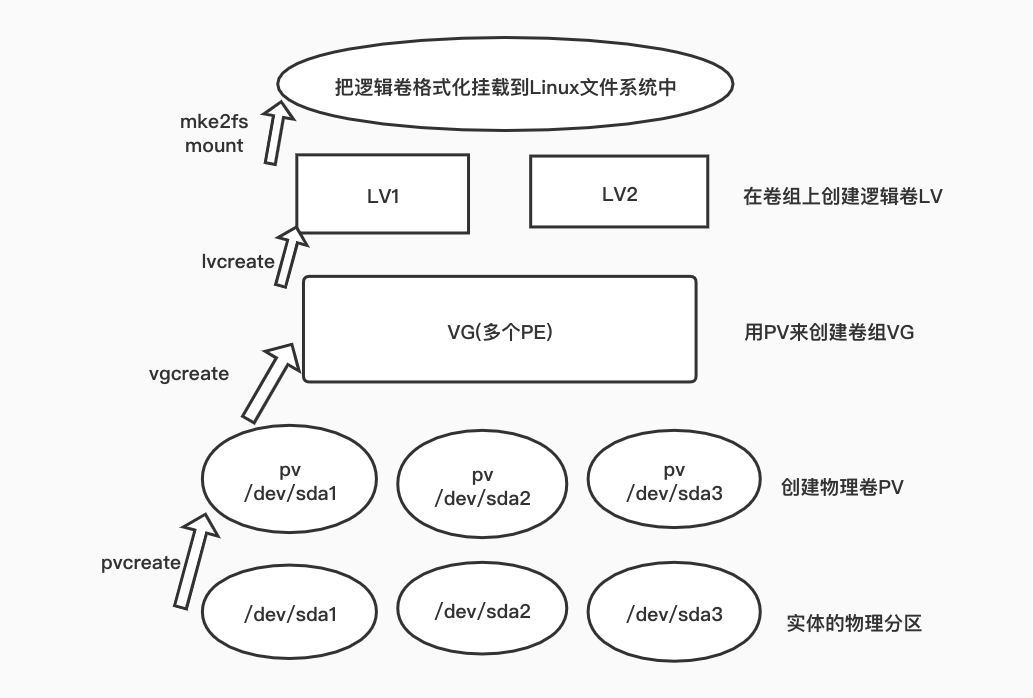 软件包 :lvm2
软件包 :lvm2
1. 制作 PV:可以对分区做、也可以对整块盘做
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# 制作
[root@localhost ~]# pvcreate /dev/sdb1 # 对分区做
[root@localhost ~]# pvcreate /dev/sdb2 # 对分区做
[root@localhost ~]# pvcreate /dev/sdb3 # 对分区做
[root@localhost ~]# pvcreate /dev/sdc # 对整块盘做
# 查看
[root@localhost ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/sdb1 lvm2 --- 1.00g 1.00g
/dev/sdb2 lvm2 --- 1.00g 1.00g
/dev/sdb3 lvm2 --- 1.00g 1.00g
/dev/sdc lvm2 --- 20.00g 20.00g
[root@localhost ~]# pvscan
PV /dev/sdb1 lvm2 [1.00 GiB]
PV /dev/sdc lvm2 [20.00 GiB]
PV /dev/sdb2 lvm2 [1.00 GiB]
PV /dev/sdb3 lvm2 [1.00 GiB]
Total: 4 [23.00 GiB] / in use: 0 [0 ] / in no VG: 4 [23.00 GiB]
|
2. 制作 VG:将 PV 划入 VG 中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 制作一个vg1:
[root@localhost ~]# vgcreate vg1 /dev/sdb1 /dev/sdc # 包含/dev/sdb1与/dev/sdc两个pv
Volume group "vg1" successfully created
[root@localhost ~]# vgs
VG #PV #LV #SN Attr VSize VFree
vg1 2 0 0 wz--n- 20.99g 20.99g
# 也可以再制作一个vg2:
[root@localhost ~]# vgcreate vg2 /dev/sdb2 /dev/sdb3 # 包含/dev/sdb2与/dev/sdb3两个pv
Volume group "vg2" successfully created
[root@localhost ~]# vgs
VG #PV #LV #SN Attr VSize VFree
vg1 2 0 0 wz--n- 20.99g 20.99g
vg2 2 0 0 wz--n- 1.99g 1.99g
[root@localhost ~]#
|
3. 创建逻辑卷 LVM
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
选项
-L #逻辑卷大小
-n #逻辑卷名字
# 从vg1中分出来逻辑卷lv1_from_vg1、lv2_from_vg1
[root@localhost ~]# lvcreate -L 100M -n lv1_from_vg1 vg1
[root@localhost ~]# lvcreate -L 200M -n lv2_from_vg1 vg1
# 从vg2中分出来一个建逻辑卷lv1_from_vg2、lv1_from_vg2
[root@localhost ~]# lvcreate -L 300M -n lv1_from_vg2 vg2
[root@localhost ~]# lvcreate -L 400M -n lv2_from_vg2 vg2
# 查看
[root@localhost ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
lv1_from_vg1 vg1 -wi-a----- 100.00m
lv2_from_vg1 vg1 -wi-a----- 200.00m
lv1_from_vg2 vg2 -wi-a----- 300.00m
lv2_from_vg2 vg2 -wi-a----- 400.00m
# 把vg的100%空间都给lv
lvcreate -l 100%VG -n lv的名字 vg的名字
|
格式与挂载
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
[root@localhost ~]# mkfs.xfs /dev/vg1/lv1_from_vg1
[root@localhost ~]# mkfs.xfs /dev/vg1/lv2_from_vg1
[root@localhost ~]# mkfs.xfs /dev/vg2/lv1_from_vg2
[root@localhost ~]# mkfs.xfs /dev/vg2/lv2_from_vg2
[root@localhost ~]# mount /dev/vg1/lv1_from_vg1 /test1/
[root@localhost ~]# mount /dev/vg1/lv2_from_vg1 /test2/
[root@localhost ~]#
[root@localhost ~]# mount /dev/vg2/lv1_from_vg2 /test3/
[root@localhost ~]# mount /dev/vg2/lv2_from_vg2 /test4/
# 查看
[root@localhost ~]# df
文件系统 1K-块 已用 可用 已用% 挂载点
...
/dev/mapper/vg1-lv1_from_vg1 98980 5344 93636 6% /test1
/dev/mapper/vg1-lv2_from_vg1 201380 10464 190916 6% /test2
/dev/mapper/vg2-lv1_from_vg2 303780 15584 288196 6% /test3
/dev/mapper/vg2-lv2_from_vg2 406180 20704 385476 6% /test4
[root@localhost ~]#
|
在线动态扩容
在不用卸载的情况下完成扩容
1
2
|
lvextend -L [+]MGT /dev/VG_NAME/VL_NAME
# 注意:-L 100M 与 -L +100M不是一个意思,后者代表在原有的基础上扩容
|
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 1、新增一块盘或者一个分区
fdisk /dev/sdb ......
partprobe
ls /dev/sdb4
# 2、新增一个pv
[root@localhost ~]# pvcreate /dev/sdb4
# 3、把新增的pv扩到vg2里
[root@localhost ~]# vgextend vg2 /dev/sdb4
[root@localhost ~]# vgs # 可以看到vg2扩容了
# 4、接下来对lv1_from_vg2扩容
[root@localhost ~]# lvextend -L +1000M /dev/vg2/lv1_from_vg2
[root@localhost ~]# xfs_growfs /dev/vg2/lv1_from_vg2 # 扩展逻辑卷后需要更新fs文件系统
|
在线缩容与删除
不要缩容!!!并且xfs干脆不支持缩容
1
2
3
4
5
6
7
8
9
10
11
|
lvreduce -L [-]MGT /dev/VG_NAME/LV_NAME 缩减逻辑卷
# 删除lv之前需要先卸载挂载点
[root@localhost ~]# umount /test3
[root@localhost ~]# lvremove /dev/vg2/lv1_from_vg2
# 删vg
[root@localhost ~]# vgremove vg2
# 删pv:只能删掉那些不属于任何vg的pv
[root@localhost ~]# pvremove /dev/sdb2
[root@localhost ~]# pvremove /dev/sdb3
|
快照
LVM 机制还提供了对 LV 做快照的功能,也就是说可以给文件系统做一个备份,这也是设计 LVM 快照的主要目的。LVM 的快照功能采用写时复制技术(Copy-On-Write,COW),这比传统的备份技术的效率要高很多。创建快照时不用停止服务,就可以对数据进行备份。说明:LVM 还支持 thin 类型的快照,但是本文中的快照都是指 COW 类型的快照。
LVM 采用的写时复制,是指当 LVM 快照创建的时候,仅创建到实际数据的 inode 的硬链接(hark-link)而已。只要实际的数据没有改变,快照就只包含指向数据的 inode 的指针,而非数据本身。快照会跟踪原始卷中块的改变,一旦你更改了快照对应的文件或目录,这个时候原始卷上将要改变的数据会在改变之前拷贝到快照预留的空间。
lvm快照的原理:
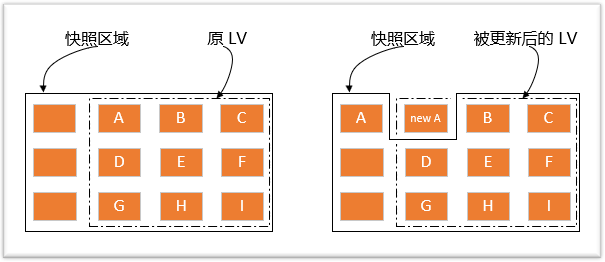
创建快照实际上也是创建了一个逻辑卷,只不过该卷的属性与普通逻辑卷的属性有些不一样。我们可以通过上图来理解快照数据卷(图中的实线框表示快照区域,虚线框表示文件系统):
左图为最初创建的快照数据卷状况,LVM 会预留一个区域 (比如左图的左侧三个 PE 区块) 作为数据存放处。此时快照数据卷内并没有任何数据,而快照数据卷与源数据卷共享所有的 PE 数据,因此你会看到快照数据卷的内容与源数据卷中的内容是一模一样的。等到系统运行一阵子后,假设 A 区域的数据被更新了(上面右图所示),则更新前系统会将该区域的数据移动到快照数据卷中,所以在右图的快照数据卷中被占用了一块 PE 成为 A,而其他 B 到 I 的区块则还是与源数据卷共享!
由于快照区与原本的 LV 共享很多 PE 区块,因此快照区与被快照的 LV 必须要在同一个 VG 上头,下面两点非常重要:
1、VG中需要预留存放快照本身的空间,不能全部被占满。
2、快照所在的 VG 必须与被备份的 LV 相同,否则创建快照会失败。
快照的本质就是一个特殊的 lv,创建快照后,如果源数据卷中的文件被更新了,会将老数据赋给快照的空间,这就要求快照的空间也是够用的
示例1:利用快照恢复单个文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
# 1、准备好初始数据
[root@localhost ~]# df
文件系统 1K-块 已用 可用 已用% 挂载点
。。。。。。
/dev/mapper/vg1-lv1_from_vg1 98980 5348 93632 6% /test1
[root@localhost ~]# echo "hello egon" > /test1/1.txt
# 2、查看vg1容量是否充足
lv1_from_vg1 属于卷组vg1,而vg1有足够的容量来分配给快照卷
[root@localhost ~]# vgs
VG #PV #LV #SN Attr VSize VFree
vg1 2 2 0 wz--n- 20.99g <20.70g
[root@localhost ~]#
# 3、在vg1卷组里创建一个lv1_from_vg1的逻辑卷
[root@localhost ~]# lvcreate -L 1G -s -n lv1_from_vg1_snap /dev/vg1/lv1_from_vg1
# 4、查看
[root@localhost ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
lv1_from_vg1 vg1 owi-aos--- 100.00m
lv1_from_vg1_snap vg1 swi-a-s--- 104.00m lv1_from_vg1 0.01
。。。。。。
# 5、修改文件/test/1.txt
[root@localhost ~]# echo "egon say ladygaga" >> /test1/1.txt
[root@localhost ~]# cat /test1/1.txt
hello egon
egon say ladygaga
# 6、恢复数据
挂载快照,注意:快照在挂载的时候由于和原来的lvm是同一个UUID,而XFS是不允许相同UUID的文件系统挂载,所以需要加选项 -o nouuid
[root@localhost ~]# mount -o nouuid /dev/vg1/lv1_from_vg1_snap /opt/
[root@localhost ~]# cat /opt/1.txt
hello egon
[root@localhost ~]# cp /opt/1.txt /test1/1.txt
cp:是否覆盖"/test1/1.txt"? y
[root@localhost ~]# cat /test1/1.txt
hello egon
[root@localhost ~]#
|
示例2:如果要恢复的文件个数过多,可以直接合并
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
mount /dev/vg1/lv1_from_vg1 /test1/
echo hello egon > /test1/1.txt
# -L指快照的大小,不能超过源的大小,超了也没啥用
lvcreate -L 1G -s -n lv1_from_vg1_snap /dev/vg1/lv1_from_vg1
echo aaaa >> /test1/1.txtecho aaaa >> /test1/1.txt
echo aaaa >> /test1/1.txt
echo aaaa >> /test1/1.txt
echo aaaa >> /test1/1.txt
echo aaaa >> /test1/1.txt
mount -o nouuid /dev/vg1/lv1_from_vg1_snap /opt/
[root@localhost ~]# cat /opt/1.txt
hello egon
[root@localhost ~]# cat /test1/1.txt
hello egon
aaaa
aaaa
aaaa
aaaa
aaaa
先卸载数据源与快照,再进行合并,快照会自动删除,一次性的
[root@localhost ~]# umount /test1
[root@localhost ~]# umount /opt
[root@localhost ~]# lvconvert --mergesnapshot /dev/vg1/lv1_from_vg1_snap
[root@localhost ~]# mount /dev/vg1/lv1_from_vg1 /test1/
[root@localhost ~]# cat /test1/1.txt # 数据还原回来了
hello egon
|
